I WANT TO
LEARN!
A digital artefact by
Li Yize 201936460
He Dengyijia 201946830
Chen Meng 201940245
Zhao Xinke 202008659
I WANT TO LEARN!
Introduction:
This project examines gender inequality in education in China. Although the policy of promoting education has significantly improved educational attainment and reduced inequality, inequality in educational attainment remains significant (Yang et al., 2014). Because education is usually understood as a system that is fair and merit-based, in reality, women's education, completion of education, and opportunities to change their life trajectory are still influenced by gender factors (Stromquist, 2006). The development of compulsory education has always been embedded in existing social relations, patriarchal culture, differences in resource allocation, and gender norms around marriage and care, from the background of educational practice. Against this background, girls' educational opportunities are often limited by family decision-making, local customs, and costs (Sheng, 2012).
Based on this, this project hopes to re-understand what “educational equality” is and explain that women still face restrictions when data seems to be improving. We first use thematic analysis to summarise core issues, then use digital media narrative to present them more clearly. The target audience is young people aged 18–25, who are familiar with education and active on social media. They can relate to the topic, help spread the project, and participate through sharing and donating books.
Method:
This project explores gender inequality in Chinese education in combination with statistical data combing and thematic analysis. Statistical data mainly come from government reports and relevant information released by international organisations. However, official statistics often show a trend of gradually narrowing the gender gap in the field of education, thus constructing a macro narrative that inequality is disappearing. This kind of data summarises the development of education through quantitative indicators, but its focus is mainly on trends and proportions. From the perspective of data feminism, data is not neutral but reflects specific focuses and power structures (D'Ignazio and Klein, 2020). Therefore, the narrowing gap presented by statistics does not mean the disappearance of inequality, but may cover up structural problems.
On this basis, this project takes thematic analysis as a method. The materials come from news reports and academic literature, providing more specific cases and turning research from abstract data to real experience. The study retrieves materials around keywords such as "Unequal distribution of family resources ", "Traditional gender concepts Discrimination ", "Limitations of the educational structure in urban and rural areas ", and "Early marriage leads to interruption of education ". These keywords are adjusted in the process of reading and sorting materials.
In the analysis stage, the study identifies repeated content and narrative style through reading and comparison, and summarises common patterns to form analytical topics, revealing structural inequality under the superficial equality narrative.
Findings:
Through the subject analysis of statistical data and text materials, it can be found that gender inequality in the field of education does not disappear with the improvement of dominant indicators, but persists through a variety of daily mechanisms. These inequalities do not always manifest as direct denial of educational opportunities, but are gradually accumulated and reproduced in the process of education through resource allocation, gender concepts, regional structure, and life paths.
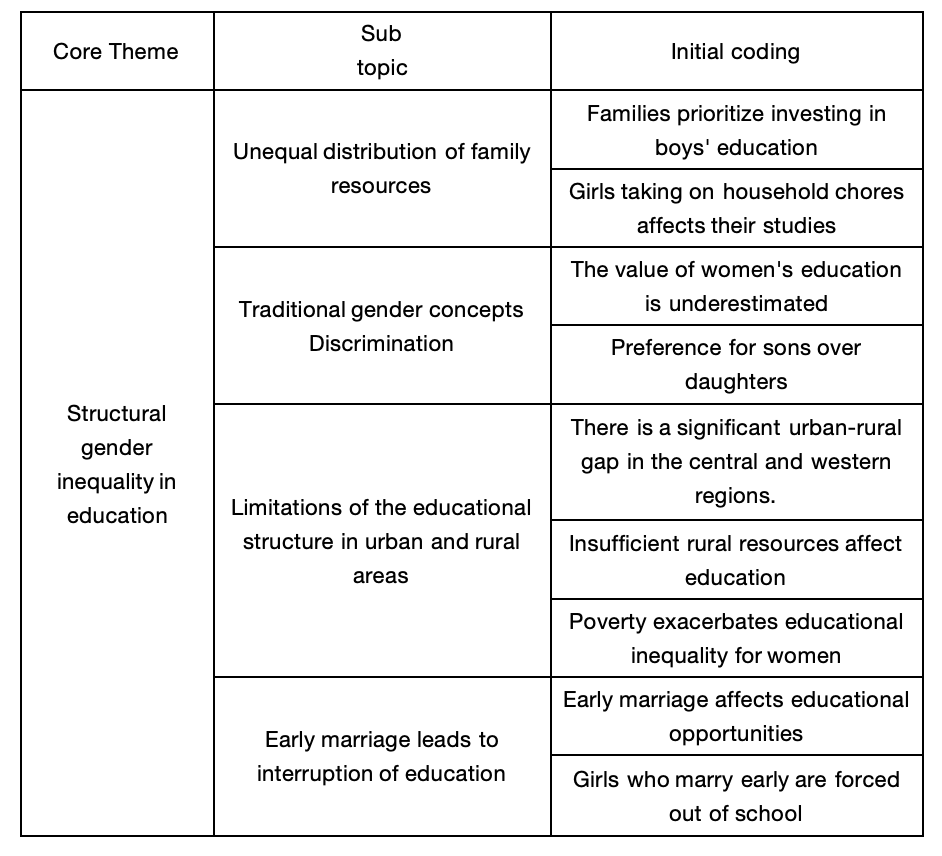
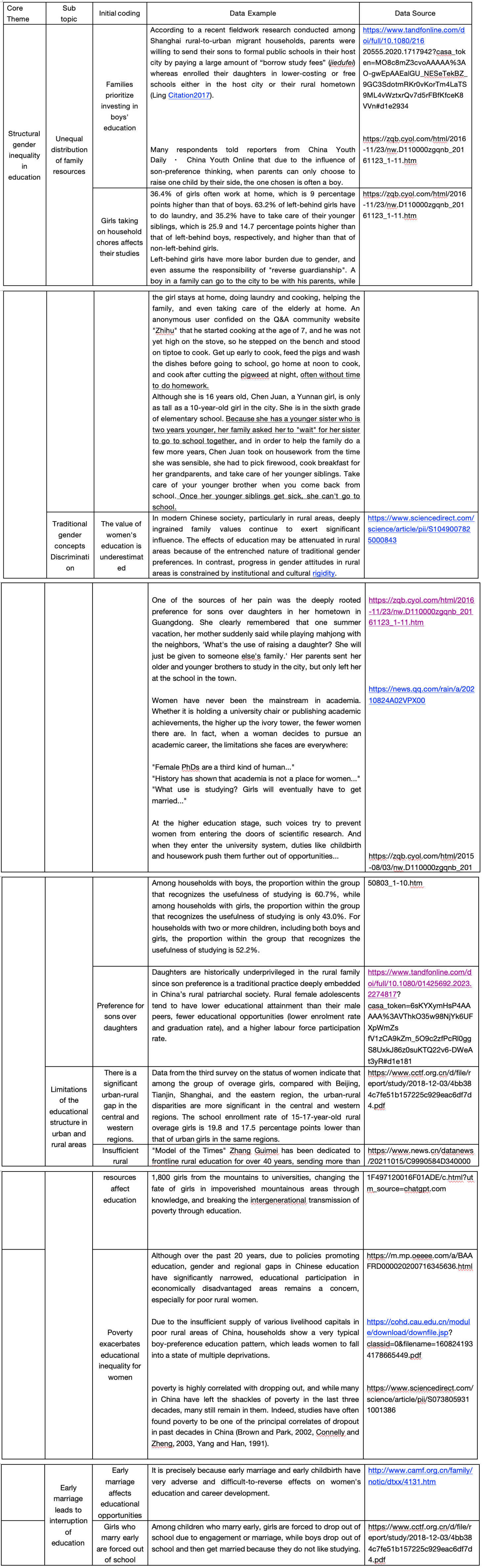
Figure 1: Thematic analysis table
Theme 1: Unequal distribution of family resources
At the family level, the distribution of educational resources shows obvious gender bias, which is not only reflected in economic input but also in the distribution of time and labour. On the one hand, at the level of education investment, the materials show that families often give priority to ensuring boys' educational opportunities under the condition of limited resources. For example, a news report pointed out that parents are more willing to pay a higher cost for boys to enter urban public schools, while girls are assigned to lower-cost schools (Liu et al. 2020). When a family can only choose one child to take with them, boys are often given priority (Chen and Hu, 2016). On the other hand, in daily life, girls take on more housework and care, which directly affects their learning conditions. Data shows that 36.4% of girls often participate in housework, higher than boys. Among the left-behind children, 63.2% of girls need to do laundry, and 35.2% need to take care of their younger brothers and sisters (Research Group of China Youth and Children Research Centre, 2015). In specific cases, some girls need to cook, feed pigs, take care of their families, and even can't go to school when their siblings are sick, this long-term lack of stable study time (Chen and Hu, 2016).
This shows that educational inequality is not necessarily manifested in the lack of enrolment, but gradually weakens women's learning conditions through the occupation of time and energy.
Theme 2: Traditional gender concepts Discrimination
There are a large number of expressions that directly reflect gender concepts in the materials, such as "what's the use of raising a daughter", "what's the use of a girl's study", "in the end, they still have to get married", etc. These words repeatedly appear in the context of family and society (Chen and Hu, 2016). At the same time, the relevant survey data shows that in families with boys, the recognition of the usefulness of reading is significantly higher than that of families with only girls (60.7% vs 43.0%) (Li and Wu, 2015). This shows that the value of education itself has been gendered.
In the allocation of educational resources or decision-making, reducing investment in girls is often interpreted as a realistic choice, thus covering up the gender bias. Therefore, inequality is constantly naturalised at the conceptual level, making it difficult to identify as a problem.
Theme 3: Limitations of the educational structure in urban and rural areas
In the process of education, women are more likely to interrupt their studies due to marriage and family responsibilities. The materials show that in some areas, girls are forced to leave school because of engagement or marriage, while men are more likely to get married after dropping out (China Children and Teenagers' Fund, 2018). This difference shows that marriage plays a role in a structural turning point in the path of women's education (China Marriage and Family Research Association, n.d.). For women, marriage is not only a change in the stage of life, but also a shift from the education system to a family role. In addition, family responsibilities gradually compress women's educational space at the daily level. Girls take on care and housework earlier, study time is reduced, grades decline, and they finally drop out of school. This process is often only expressed as the dropout rate in statistics, and the gender mechanism behind it is covered up.
Theme 4:Early marriage leads to interruption of education
Although statistics at the national level show that the gender gap has narrowed, this average result to some extent obscures the significant differences between different regions. According to a survey by the China Children and Teenagers’ Fund (2018), in the central and western regions, the schooling rate of older girls in rural areas is significantly lower than that of urban girls in the same region, with a gap of about 17% to 20%. This gap not only reflects gender inequality, but also reflects the structural disadvantage under the joint effect of gender, geographical, and economic conditions (China Children and Teenagers' Fund, 2018). At the same time, there are widespread problems of insufficient educational resources in rural areas. These structural restrictions further compress the educational opportunities of girls (China Children and Teenagers' Fund, 2018). In addition, poverty factors have played an amplifying role in this process. Relevant studies show that there is a significant correlation between poverty and dropout, which is one of the important factors affecting the educational opportunities of Chinese children (Yi et al., 2012).
Therefore, gender inequality in education should be understood as a multi-dimensional structural problem. Girls in underdeveloped rural areas actually suffer from the superimposed impact of multiple adverse, and the national average data weakens or even obscures the real situation of this group to a certain extent.
Response:
At first, we understood inequality more as a question of whether we can receive education, but through the analysis of statistics and text materials, I realised that inequality often does not appear in the form of direct deprivation of opportunities, but through the allocation of family resources, gender concept, marriage expectations and the daily division of labour system, gradually accumulated and reproduced in the process of education. This understanding also made me re-examine the conclusion that the gap is narrowing presented by official data, and to understand that the improvement of macro indicators does not mean that structural inequality has disappeared.
This analysis directly affects the narrative style of our choice of digital media works. At first, we tried to use Twine as the main tool for interactive narrative, so that the audience could participate in the development of the story and feel the unequal situation of rural girls in educational opportunities. However, we found that its interface and logic are difficult for audiences who do not understand the tool, which affects the expression of our content. At the same time, striking a balance between narrative and interactivity presents a significant challenge. If too much emphasis is placed on the narrative, interactivity suffers; conversely, if too much emphasis is placed on choice, emotional expression may be compromised.
Social media information needs to be concise, easy to share, and targeted to a specific audience, while Twine is the opposite. So later, we chose digital tools such as Genially to optimise page layout and user experience, and gradually transform complex issues into short, specific, and easy-to-understand content to better fit the reading habits of young audiences.
In this project, we will consciously integrate the four core themes obtained from the study into the narrative structure of the "diary", so that the research findings can be transformed into specific and persible personal experiences. First of all, in theme 1, we intuitively present the inequality of the distribution of resources within the family through the plot that the younger brother can go to school, but "I" am left at home in the opening. Secondly, theme 2 is reflected through the dialogue between relatives persuading them to drop out of school, so that social concepts are naturally embedded in the narrative in the form of everyday language. Third, in terms of theme 3, we have designed the plot of the need to undertake housework, take care of the family, and mention dowry and marriage, showing the real dilemma that girls are constantly pulled back to the family role in the process of growing up. Finally, theme 4 is implicitly presented through the overall background, such as the rural environment, the lack of educational resources, and the need to rely on teachers and subsidies to continue learning, reflecting the multiple effects of structural inequality. Through such a design, we transform the research findings at the macro level into micro narratives, so that the audience can understand the complexity and reality of these problems in specific situations and emotional experiences.
In the process of using Genially design, we redesigned the project for these problems, transformed the presentation form into a more intuitive and visually impactful style, and reconstructed the content in the form of a "diary" to make the story clearer and easier to read. At the same time, by setting the "Search" button next to the text, users can click to view the relevant true story prototypes, enhance the interactive experience, and make the text more emotionally infectious by adjusting the language style. These adjustments have improved the readability and dissemination of the work.
If there is more time in the future, we hope to further improve the project, such as adding elements such as sound or animation, and collecting feedback through user testing to optimise the interaction design. This project makes us realise that digital media can not only convey information, but also deepen the audience's understanding of social issues.
Reference
Chen, M. 2017. Left-behind girls struggle for education. China Daily. [Online]. 2 March. [Accessed 28 March 2026]. Available at: http://www.chinadaily.com.cn/newsrepublic/2017-03/02/content_28415392.htm
Chen, Y.陈轶男. and Hu, N.胡宁. 2016. nv tong zhi tong 女童之痛 China Youth Daily.[Online]. 23 November. [Accessed 10 March]. Available from: https://zqb.cyol.com/html/2016-11/23/nw.D110000zgqnb_20161123_1-11.htm
China Children and Teenagers' Fund. 2018. Zhongguo nütong jiaoyu yu fazhan xuqiu yanjiu baogao 2015 中国女童教育与发展需求研究报告2015. [Online]. 3 December. [Accessed 26 March 2026]. Available from: https://www.cctf.org.cn/d/file/report/study/2018-12-03/4bb384c7fe51b157225c929eac6df7d4.pdf
China Marriage and Family Research Association. Ezhi “shaonü mama” xianxiang shi quanshehui de gongtong zeren 遏制“少女妈妈”现象是全社会的共同责任. China Marriage and Family Research Association. [Online]. [Accessed 26 March 2026]. Available from: http://www.camf.org.cn/family/notic/dtxx/4131.htm
D’Ignazio, C. and Klein, L.F. 2020. Data feminism. Cambridge, Massachusetts: The MIT Press.
Li, D. 2020. Woman devoted to girls’ education in the mountains. China Daily. [Online]. 1 July. [Accessed 28 March 2026]. Available at: https://www.chinadaily.com.cn/a/202007/03/WS5efee839a31083481725719a_1.html
Li, T.李涛. and Wu, Z.邬志辉. 2015. Bie rang xin “dushu wuyong lun” silie xiangtu Zhongguo——Xibu yige bianyuan cunzhuang de diaocha别让新“读书无用论”撕裂乡土中国——西部一个边远村庄的调查. China Youth Daily. [Online]. 3 August. [Accessed 26 March 2026]. Available from: https://zqb.cyol.com/html/2015-08/03/nw.D110000zgqnb_20150803_1-10.htm
Li, Z.李志城. 2025. Duobumen liandong jingzhun pufa chenggong huajie weichengnianren “tonghun” fengxian 多部门联动精准普法 成功化解未成年人“童婚”风险. Gengma Autonomous County Legal Education Channel. [Online]. 16 December. [Accessed 30 March 2026]. Available at: https://mp.weixin.qq.com/s?search_click_id=1620269981077107223-1773839781498-5699604863&__biz=MzIzMDUzMzkyMw==&mid=2247501293&idx=1&sn=17de0226233d7e0a60b57611d29c6a45&chksm=e948c17a1ae9f0b4de0aca82ddfb52326f5fdabdb094a29e96a8b76c9930748f6aca138573a0&scene=7#rd
Liu, Y., Jiang, Q. and Chen, F. 2020. Children’s gender and parental educational strategies in rural and urban China: the moderating roles of sibship size and family resources, Chinese Sociological Review, 52(3), pp. 239–268. doi: https://doi.org/10.1080/21620555.2020.1717942
Lu, F. 2024. China girl, 16, forced by parents to quit school and work helped to resume studies by officials, gets free, safe-haven flat from online influencer. South China Morning Post. [Online]. 7 March. [Accessed 30 March 2026]. Available at: https://www.scmp.com/news/people-culture/gender-diversity/article/3253631/china-girl-16-forced-parents-quit-school-and-work-helped-resume-studies-officials-gets-free-safe
Research Group of China Youth and Children Research Center. 2015. Zhongguo nongcun liushou ertong shengcun xianzhuang diaocha 中国农村留守儿童生存现状调查. The Paper. [Online]. 11 June. [Accessed 26 April 2026]. Available from: https://m.thepaper.cn/newsDetail_forward_1340812
Sheng, X. 2012. Cultural capital and gender differences in parental involvement in children’s schooling and higher education choice in China. Gender and Education, 24(2), pp.131–146. doi:https://doi.org/10.1080/09540253.2011.582033
Stromquist, N.P. 2006. Gender, education and the possibility of transformative knowledge. Compare: A Journal of Comparative and International Education,36(2), pp.145–161. doi:https://doi.org/10.1080/03057920600741131
Yang, J., Huang, X. and Liu, X. 2014. An analysis of education inequality in China. International Journal of Educational Development, 37(37), pp.2–10. doi:https://doi.org/10.1016/j.ijedudev.2014.03.002
Yi, H., Zhang, L., Luo, R., Shi, Y., Mo, D., Chen, X., Brinton, C. and Rozelle, S. 2012. Dropping out: Why are students leaving junior high in China’s poor rural areas? International Journal of Educational Development. [Online]. 32(4), pp.555–563. doi:https://doi.org/10.1016/j.ijedudev.2011.09.002
Zhang, Z. and Huang, Z. 2022. Promises of marriage give way to girls’ education. China Daily. [Online]. 26 September. [Accessed 28 March 2026]. Available at: http://global.chinadaily.com.cn/a/202209/26/WS633171cca310fd2b29e79cd3.html
Attachment
“Some girls are not pushed out of education all at once. They are erased line by line, page by page, until silence begins to look natural.”